数字协同、数据驱动,社会发展大趋势
大数据开发
应用领域






 IT服务
IT服务
 智能家居
智能家居
 数据服务
数据服务
 物联网
物联网
 自动驾驶
自动驾驶
 电子竞技
电子竞技
 远程医疗
远程医疗
 即时通信
即时通信
人才紧缺,更易突破薪资瓶颈
大数据开发全国热门地区平均月薪
* 全国每日新增大数据岗位 1.2 万 / 天
数据来源:职友集
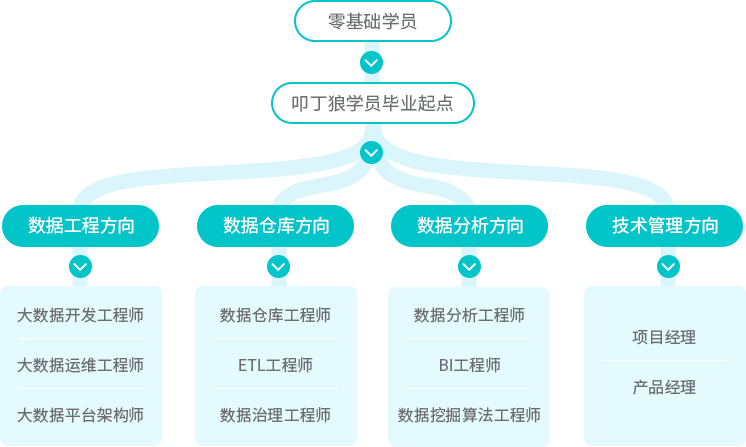
叩丁狼大数据职业发展方向
四大优势为零基础学员保驾护航
真懂你
够真实
教双语
拼实战
全新课程体系
从零培养懂业务, 能架构的中高级大数据人才

夯实Python编程基础和编程思维,熟练编写Python程序
掌握基本的数据分析能力和ETL数据仓库的处理能力
掌握Hadoop开发能力,能够胜任企业级数仓基本构建和离线数据仓库开发
掌握短视频行业的业务逻辑与必备开发技能,通过Spark离线业务开发的项目实战,具备完整的大数据项目开发流程与设计
掌握NoSQL数据库的开发技能,为下一阶段的实时计算开发提供支撑
掌握阅读和修改大数据框架源码的能力,具备通过Java开发大数据应用的能力
熟悉医疗大数据行业的业务流程,并具备实时项目的大数据系统架构,系统开发和设计能力
第一阶段:Python编程

阶段内容

阶段知识点
核心知识点
1、深入理解Python核心基础
2、掌握面向对象OOP设计思想
3、掌握Python的数据结构列表、元组、字典、集合
4、掌握JSON文件数据操作和异常处理
5、理解Python的高级操作如闭包,单例,网络编程等
6、掌握git的核心操作
第二阶段:大数据基础
阶段内容
阶段知识点
核心知识点
1、具备Linux操作系统的基本管理知识
2、熟练掌握shell脚本编程
3、熟练掌握数据库操作以及各种复杂查询技术
4、掌握ETL数据仓库的处理和分析
第三阶段:大数据治理
阶段内容
阶段知识点
核心知识点
1、分布式文件存储系统HDFS
2、分布式计算MapReduce
3、MapReduce的架构设计和内核原理
4、HDFS的分布式存储的架构设计和内核原理
5、分布式资源调度YARN的调度流程, 调度策略
6、Hive的分区表,外部表,临时表
7、性能调优
8、在线视频点播平台项目全方位实战
第四阶段:大数据离线开发
阶段内容
阶段知识点
核心知识点
1、Pandas数据分析与实战
2、PySpark的核心开发与实战
3、SparkSQL的深入讲解和应用
4、Spark的原理和性能调优
5、短视频运行决策分析项目的全方位实战
第五阶段:NoSQL与实时技术
阶段内容
阶段知识点
核心知识点
1、Redis的缓存设计和应用实战
2、Redis的Key-Value存储的数据特性
3、Redis的高可用集群搭建
4、Kafka消息队列的应用
5、Kafka和其他组件(Flume,HBase)结合
6、HBase列式存储
第六阶段:Java编程
阶段内容
阶段知识点
核心知识点
1、掌握Java编程基础
2、具有多线程,多进程并发开发的能力
3、具有网络编程, 文件操作的基本能力
4、通过Java编写大数据的应用程序
第七阶段:大数据实时开发
阶段内容
阶段知识点
核心知识点
1、Flink实时计算的开发与实战
2、Flink的流批一体API的高级应用
3、Flink的容错机制Checkpoint
4、Flink的多流Join
5、医疗健康实时项目的全流程开发和设计
真项目 真实战 塑造真能力
从零培养懂业务, 能架构的中高级大数据人才
基于 Hive 的狼码教育
离线分析实战项目
基于 Spark 的短视频
运营决策分析离线实战项目
基于 Flink 的互联网医院
平台实时实战项目
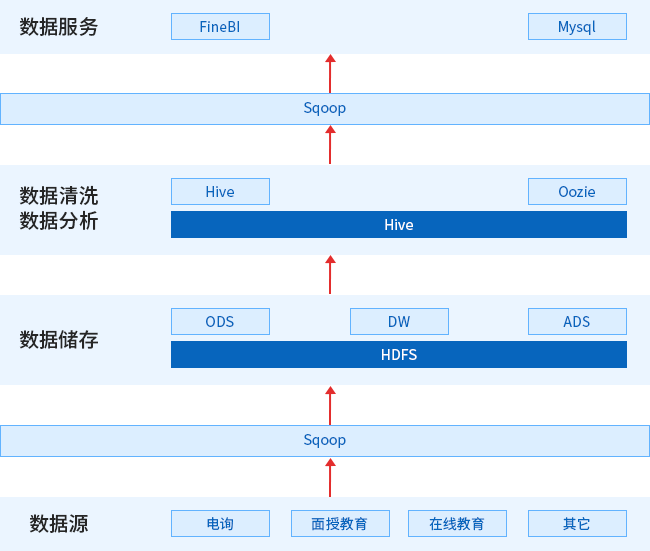
基于Hive的狼码教育离线分析实战项目
狼码教育离线分析系统项目, 是一个借鉴狼码教育公司系统的实际业务场景,引入海量的访问数据和业务数据, 采用当前企业最热门的大数据主流技术, 从0到1开始构建好一套完整的离线数据仓库,然后进行数据分析,并使用FineBI显示分析结果的项目。
技术点:
- 1、将近40个运营指标的分析
- 2、访问指标, 咨询指标, 意向指标以及学生出勤指标的分析
- 3、数据仓库维度建模 ODS-->DIM-->DWD-->DWM-->DWS-->ADS
- 4、使用Sqoop 完成数据抽取工作
- 5、使用Hive、Oozie完成数据清洗和转换工作
- 6、使用 FineBI完成数据可视化
- 7、使用 Kafka完成数据处理的高可用和异步解耦
- 8、使用Apache的Mysql完成元数据的管理和共享
- 9、使用Cloudera Manager完成整个大数据平台的监控和分析
- 10、使用分布式存储HDFS完成数据的存储
- 11、使用Hive-on-MapReduce 完成Hive离线大数据分析任务
学习目标:
- 1、掌握项目的各个核心业务分析
- 2、熟练数据建模的设计与实现
- 3、熟练掌握企业中用的核心的大数据开发技术
- 4、熟练掌握大数据开发的整个流程
- 5、理解数据仓库的特点
- 6、理解数据仓库系统架构
- 7、理解指标与维度
- 8、理解下钻与上卷
- 9、理解事实表与维度表
- 10、理解星型模型和雪花模型
- 11、理解缓慢渐变维
- 12、掌握数据仓库的分层方法
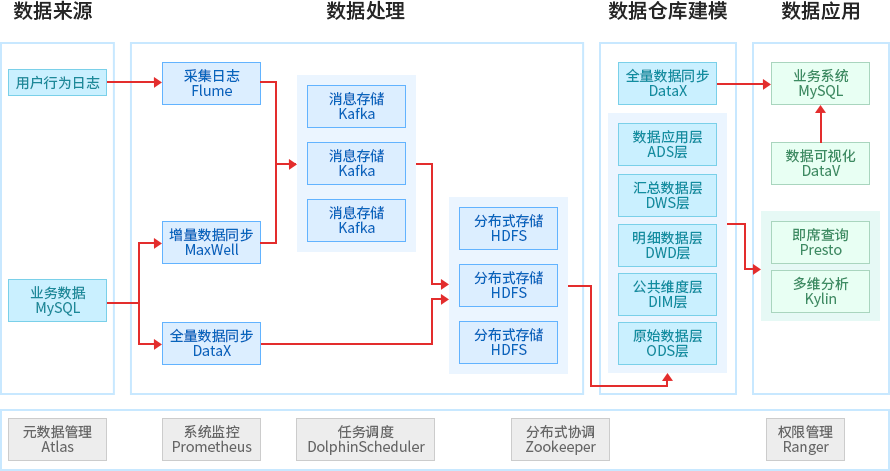
基于Spark的短视频运营决策分析离线实战项目
该短视频项目定位于中小城市的普通移动互联网用户,通过“裂变网赚”模式,以人传人的方式快速积累用户,完成用户爆发式的指数级增长,因此视频以内容消耗为主,区别于抖音以内容创作+内容消耗,通过算法分析完成精准推送的的模式。 该项目基于对短视频领域的真实业务深入调研和分析, 引入真实完整业务系统中的业务数据和用户行为数据,采用大数据主流技术, 以及完整的数据仓库的建模和设计, 通过运营分析指标为公司领导战略决策提供关键依据。
技术点:
- 1、将近120个运营指标的分析
- 2、账户指标, 用户指标, 风控指标,红包指标以及短视频播放指标的分析
- 3、数据仓库维度建模 ODS-->DIM-->DWD-->DWS-->ADS
- 4、使用Flume采集用户行为数据, 并且自定义拦截器添加一个时间优化处理
- 5、使用DataX完成业务数据库的采集工作
- 6、使用 Quick BI完成数据可视化
- 7、使用 Kafka完成数据处理的高可用和异步解耦
- 8、使用Apache的顶级开源项目DolphinScheduler完成任务调度
- 9、使用Apache的顶级开源项目Atlas完成元数据的管理和共享
- 10、使用Prometheus完成整个大数据平台的监控和分析
- 11、使用分布式存储HDFS完成数据的存储
- 11、使用Hive-on-Spark 完成Hive性能的高速提升
- 11、使用Kylin+Parquet完成OLAP的多维数据分析
- 11、使用PB级别的海量数据分析工具Presto进行即席数据分析
学习目标:
- 1、掌握短视频的各个核心业务分析
- 2、熟练数据建模的设计与实现
- 3、熟练掌握企业中用的核心的大数据开发技术
- 4、熟练掌握大数据开发的整个流程
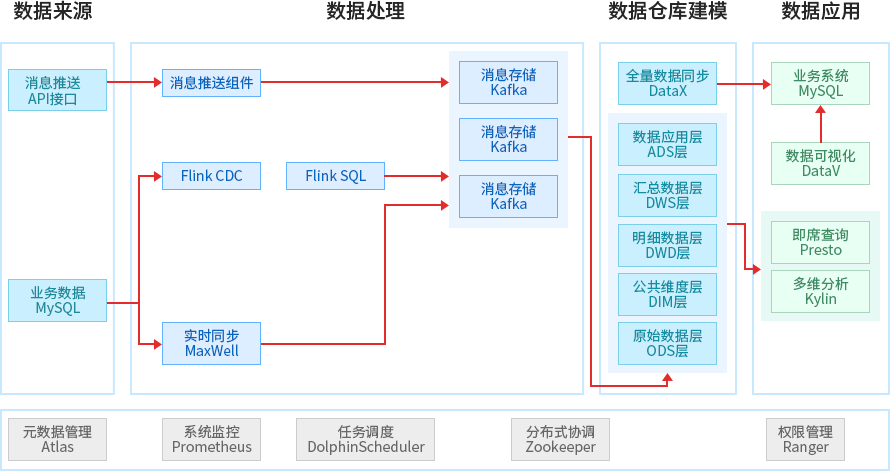
基于Flink的互联网医院平台实时实战项目
通过对互联网医院的业务分析和调研,使用MaxWell实时采集用户端、 商家端以及运营端的业务数据同步到消息中心Kafka,使用Kafka作为实时数据的数据仓库核心存储,使用DataV同步数据到应用层,使用QuickBI完成数据的可视化,并且在整个项目中使用Prometheus、Atlas、Ranger等完成大数据平台治理,保证整个项目的安全和权限,系统性能监控,元数据血缘关系的可追溯。
技术点:
- 1、统计将近80个指标的分析和设计
- 2、使用MaxWell完成数据库数据到数据仓库的实时同步
- 3、使用Kafka消息中间件作为消息缓存
- 4、使用Zookeeper作为分布式组件的一个协调
- 5、使用 Kafka完成数据处理的高可用和异步解耦
- 6、使用FlinkCDC实现数据的全量和增量的同步
- 7、使用FlinkSQL完成业务指标的统计和分析
- 8、使用Apache的顶级开源项目DolphinScheduler完成任务调度
- 9、使用Apache的顶级开源项目Atlas完成元数据的管理和共享
- 10、使用Prometheus完成整个大数据平台的监控和分析
学习目标:
- 1、实时数仓平台搭建
- 2、实时数仓模型设计
- 3、医疗行业核心指标的设计和分析
- 4、Flink平台的构建和设计实现, 具备构建PB级别数量计算引擎
- 5、具备大数据技术选型和相关参数的调优能力
叩丁狼大数据课程提供
阿里云EMR计算资源和大数据治理平台DataWorks,助你快速掌握

智能数据建模

全域数据集成

高校数据开发

主动数据资料

全面数据安全

快速数据分析
一次学习终身服务
叩丁狼对每个学生都较真
其他机构
班级管理
签订93条《叩丁狼学员守则》制度明确严抓课堂纪律
班级管理
管理松懈课堂氛围随意、作业只靠自觉
教学质量
一线讲师、全天12小时面授教学、实打实教授真技术
教学质量
名牌讲师只用于招生宣传、实际授课讲师水平参差不齐
就业保障
签订30条《就业保障协议》、找不到对口工作直接退费
就业保障
随意承诺高薪就业、对学员后期发展不负责任
课程含金量
对比其他机构、实战内容占比超出50%
课程含金量
照本宣科教学实战项目少、还是3~5年前的技术
技术更新
毕业后可免费领取最新课程视频、实时进行技术交流
技术更新
毕业后需付费领取更新的课程视频、技术老师毕业即失联