
邂逅数据结构&算法介绍
更新时间:2018-12-11 | 阅读量(1,095)
# 邂逅数据结构&算法
> 可能你之前经常听说数据结构和算法, 但是不知道他们在讨论什么.
>
> 因为似乎我们学习编程的过程中, 没有必要了解这些, 我只是在学习基本的语法/高级语法/做出界面效果/实现复杂的逻辑.
>
> 数据结构和算法? 它是什么? 为什么它如此重要?
### 一. 什么是数据结构和算法?
> 数据结构和算法的概念还真不是那么好定义.
#### 什么是数据结构?
* 官方定义: 并没有…
* 民间定义:
* “数据结构是数据对象,以及存在于该对象的实例和 组成实例的数据元素之间的各种联系。这些联系可以
通过定义相关的函数来给出。” --- 《数据结构、算法与应用》
* “数据结构是ADT(抽象数据类型 Abstract Data Type)的物理实现。” --- 《数据结构与算法分析》
* “数据结构(data structure)是计算机中存储、组织数据的方式。通常情况下,精心选择的数据结构可以 带来最优效率的算法。” ---中文维基百科
* 从上面的定义, 我们可以发现数据结构和算法的关系非常的紧密
* 我们还是从自己的角度来认识数据结构吧:
* 在计算机中, 存储和组织数据的方式
* 我们知道, 计算机中数据量非常庞大, 如何以高效的方式组织和存储呢?
* 这就好比一个庞大的图书馆中存放了大量的书籍, 我们不仅仅要把书放进入, 还应该在合适的时候能够取出来
* 我们从摆放图书说起
* 如果是自己的书相对较少, 我们可以这样摆放

* 如果你有一家书店, 书的数量相对较多, 我们可以这样摆放

* 如果我们开了一个图书馆, 书的数量相当庞大, 我们可以这样摆放

* 图书摆放要使得两个相关操作方便实现:
* 操作1:新书怎么插入?
* 操作2: 怎么找到某本指定的书?
* 图书各种摆放方式:
* 方法1:随便放
* 操作1:哪里有空放哪里,一步到位!
* 操作2: 找某本书, 累死...
* 方法2:按照书名的拼音字母顺序排放
* 操作1: 新进一本《阿Q正传》, 按照字母顺序找到位置, 插入
* 操作2: 二分查找法
* 方法3: 把书架划分成几块区域, 按照类别存放, 类别中按照字母顺序
* 操作1: 先定类别,二分查找确定位置,移出空位
* 操作2: 先定类别,再二分查找
* 结论:
* 解决问题方法的效率, 根数据的组织方式有关
* 计算机中存储的数据量相对于图书馆的书籍来说数据量更大, 数据更加多
* 以什么样的方式, 来存储和组织我们的数据才能在使用数据时更加方便呢?
* 这就是数据结构需要考虑的问题
#### 常见的数据结构
* 比较常见的数据结构
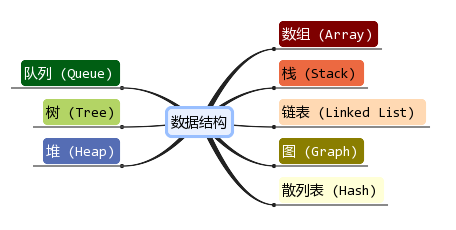
* 常见的数据结构较多, 每一种都有其对应的应用场景, 不同的数据结构的不同操作性能是不同的:
* 有的查询性能很快,有的插入速度很快,有的是插入头和尾速度很快
* 有的做范围查找很快,有的允许元素重复,有的不允许重复等等
* 在开发中如何选择,要根据具体的需求来选择
* 注意: 数据结构和语言无关, 基本常见的编程语言都有直接或者间接的使用上述常见的数据结构
* 为什么之前学习JavaScript没有接触过数据结构呢? 好像只见过数组.
* 单纯从客户程序员的角度, 我们并不需要过多的了解它们的实现细节.
* 但是简单的使用不能让我们更加灵活的使用它们. 了解真相, 你才能获得真正的自由.
#### 什么是算法?
* 算法(Algorithm)的认识
* 在之前的学习中, 我们可能学习过几种排序算法. 并且知道, 不同的算法, 执行效率是不一样的.
* 也就是说进行某些操作的过程中, 不仅仅数据的存储方式会影响效率, 算法的优劣也会影响着效率
* 那么到底什么是算法呢?
* 算法的定义:
* 一个有限指令集, 每条指令的描述不依赖于语言
* 接受一些输入(有些情况下不需要输入)
* 产生输出
* 一定在有限步骤之后终止
* 算法通俗理解:
* Algorithm这个单词本意就是解决问题的办法/步骤逻辑.
* 数据结构的实现, 离不开算法.
* 举例: 点灯不工作的解决算法
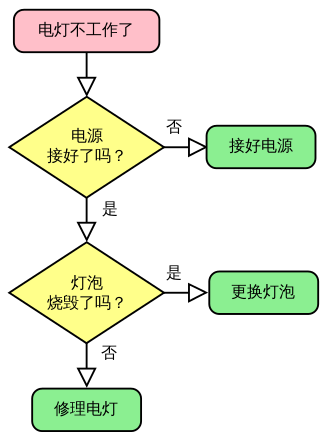
### 二. 生活中的数据结构和算法
> 前面我们提了一下生活中的数据结构和算法: 图书的摆放.
>
> 为了更加方便的插入和搜索书籍, 需要合理的组织数据, 并且通过更加高效的算法插入和查询数据.
>
> 除了这些, 生活中还有很多案例.
#### 数据结构的案例
* 快递员的快递
* 上大学期间不知道大家有没有收过快递.
* 大学的快递通常情况不是送到宿舍的(要不快递员不愿意挨着去送, 要不宿舍压根不让进), 通常快递会放在某个固定的地方, 让大家自己去拿.
* 当你跑到固定的地方拿快递, 还有两种情况: 一种自己去海量的快递中找, 另一种快递员让你报出名字, 它帮你找.
* 自己寻找相当于线性查找, 一个个挨着看吧. 当然我们人类眼睛处理数据的能力非常快, 眼观六路耳听八方, 可能很快也能找到.
* 但是比较好的方式, 应该是快递员帮我们找. 如果这个快递员动动脑筋的话, 最好的方式是对快递进行分类, 比如按照名字分类.
* 这个时候, 只要你报出名字, 它会根据姓氏立马锁定到一块快递中, 再根据名字马上帮你找到.
* 这就体现了合理的组织数据, 对于我们获取数据效率的重要性至关重要.
#### 算法的案例
* 找出线缆出问题的地方:
* 假如上海和杭州之间有一条高架线, 高架线长度是1,000,000米, 有一天高架线中有其中一米出现了故障.
* 请你想出一种算法, 可以快速定位到处问题的地方.
* 线性查找:
* 从上海的起点开始一米一米的排查, 最终一定能找到出问题的线段.
* 但是如果线段在另一头, 我们需要排查1,000,000次. 这是最坏的情况. 平均需要500,000次.
* 二分查找:
* 从中间位置开始排查, 看一下问题出在上海到中间位置, 还是中间到杭州的位置.
* 查找对应的问题后, 再从中间位置分开, 重新锁定一般的路程.
* 最坏的情况, 需要多少次可以排查完呢? 最坏的情况是20次就可以找到出问题的地方.
* 怎么计算出来的呢?log(1000000, *2*), 以2位底, 1000000的对数 ≈ 20.
* 结论:
* 你会发现, 解决问题的办法有很多. 但是好的算法对比于差的算法, 效率天壤之别.



